

For years, the prevailing wisdom in business was simple: collect more data, build a bigger moat, and your competitors cannot follow. Data was the asset that compounded over time – the more you had, the harder you were to displace.
That logic is breaking down. Not because data stopped mattering, but because the AI models now available to anyone can perform tasks that previously required large proprietary datasets – with little to no training data of their own. The moat is still there. It is just draining faster than most companies realize.
This is data inflation: the gradual erosion of the competitive value of data you already own, driven not by anything you did wrong, but by what foundation AI models can now do without you.
What is data inflation?
Data inflation is the decline in the relative competitive value of proprietary data caused by the rising capabilities of foundation AI models. As base models learn to perform tasks that once required large labeled datasets – using zero-shot or few-shot techniques – the strategic advantage of having accumulated that data shrinks, regardless of how much was collected or how long it took.
The Data Moat Assumption – and Why It Made Sense
The idea of the data moat emerged from a straightforward reality: building AI-powered products required large, labeled, proprietary datasets. If you had them and your competitor did not, you had a structural advantage that could not be quickly closed. Collecting that data took years. Labeling it took specialist time. Building models on top of it took engineering resources. The moat was real.
Companies invested heavily in this logic. Retailers built recommendation engines on years of purchase history. Manufacturers trained defect detection models on thousands of annotated product images. Logistics companies built route optimization systems on years of operational data. Each of these assets felt durable – because for a long time, they were.
The assumption held as long as one condition remained true: that performing AI-powered tasks required your own data to train on. When that condition changed, everything downstream of it changed too.
What Actually Changed: Foundation Models and the Zero-Shot Shift
The shift began with the rise of foundation models – large AI systems trained on internet-scale data across text, images, code, and other modalities. Starting around 2020 and accelerating rapidly through 2022 and beyond, these models introduced capabilities that fundamentally changed the data equation.
The most consequential of these is zero-shot and few-shot learning. A zero-shot model can perform a task it was never explicitly trained on, simply by understanding the instruction. A few-shot model needs only a handful of examples – not thousands – to generalize accurately. What this means in practice is that tasks which previously required large proprietary datasets can now be performed with a prompt and a capable base model.
The scale of this shift is reflected in economics. The cost of using the most capable AI models has dropped by more than 1,000 times in three years. Meanwhile, model quality across different providers has converged – the gap between the market leader and the second-best option is far smaller than it was in 2021. Open-source models are closing the distance further. When capability becomes cheap and widely accessible, the advantage of having the data that once built that capability shrinks accordingly.
According to the International AI Safety Report 2026, AI models now reach expert-level performance on tasks that stumped them two years ago – bachelor’s-level exam problems improved from 40% accuracy to over 90%, and postgraduate mathematics from 20% to over 80%. In programming, productivity increases run up to 30%. In our own work at Agmis, we have seen individual engineering tasks where the improvement runs higher.
Where Data Requirements Have Already Collapsed
The clearest way to understand data inflation is by comparing what was once required with what is sufficient today. Across multiple domains, the gap is no longer marginal – it is structural.
| Domain | Traditional requirement | Current capability |
|---|---|---|
| Computer vision (segmentation) | Thousands of annotated images | SAM-based models reach ~88% of human-level accuracy without task-specific data |
| Medical imaging | Full annotated dataset | 10% of annotated chest X-ray data achieves Dice score 78.87 vs. 79.13 fully supervised |
| Manufacturing defect detection | Hundreds to thousands of labeled defect images | 94% accuracy with as few as 10 examples per class |
| E-commerce classification | Curated labeled dataset + training pipeline | 74.62% accuracy zero-shot from item names alone |
| Recommendation systems | Years of behavioral data | 15% conversion increase, 20% engagement rise, 25% new product accuracy – zero training data |
| Mortality prediction (healthcare) | Large clinical dataset + domain fine-tuning | 0.927 AUC in zero-shot (ETHOS model) |
| Legal reasoning | Domain-specific fine-tuning | 90th percentile on Uniform Bar Exam – no domain-specific training |
Similar patterns extend into healthcare and scientific domains. In rare disease diagnostics, the SHEPHERD model leverages few-shot learning to significantly outperform traditional approaches, effectively doubling diagnostic efficiency. In financial systems, models such as FinGraphFL can detect credit card fraud with minimal labeled data, demonstrating that even highly sensitive tasks no longer depend on large-scale annotation.
The pattern is consistent: the data requirement for meaningful AI capability has dropped – often by an order of magnitude, and in some cases, nearly to zero. These are not isolated benchmarks or controlled experiments. They reflect results observed in production research and real-world deployments.
A Real Example: From 15,000 Labeled Images to a Prompt
One of the clearest illustrations of this shift comes from our work with Broswarm, a Lithuanian defense technology company building autonomous drone platforms for landmine detection.
Historically, building a detection system for buried explosive threats required a substantial data foundation: thousands of drone images collected across terrain types, manual annotation of each threat, training runs, and iterative refinement. The data pipeline was as demanding as the modeling itself – and the data was the moat. Programs that had it were ahead; those without could not catch up quickly.
The Agmis team working on this project applied a different approach – combining Broswarm’s X-SAR radar sensor data with computer vision models capable of learning threat signatures with far fewer labeled examples, and supplementing with synthetic data augmentation to extend the training set where real explosive samples were limited. The system identifies buried metallic, plastic, and rubber threats across four terrain types and performs surface detection from optical imagery.
The implication for data inflation is direct: the amount of labeled proprietary data required to reach high detection accuracy is a fraction of what it would have been three years ago. What remains valuable is not the volume of past images, but the specific operational context – real terrain variation, actual sensor conditions, edge cases that no synthetic dataset fully captures. The volume requirement collapsed. The specificity requirement remained.
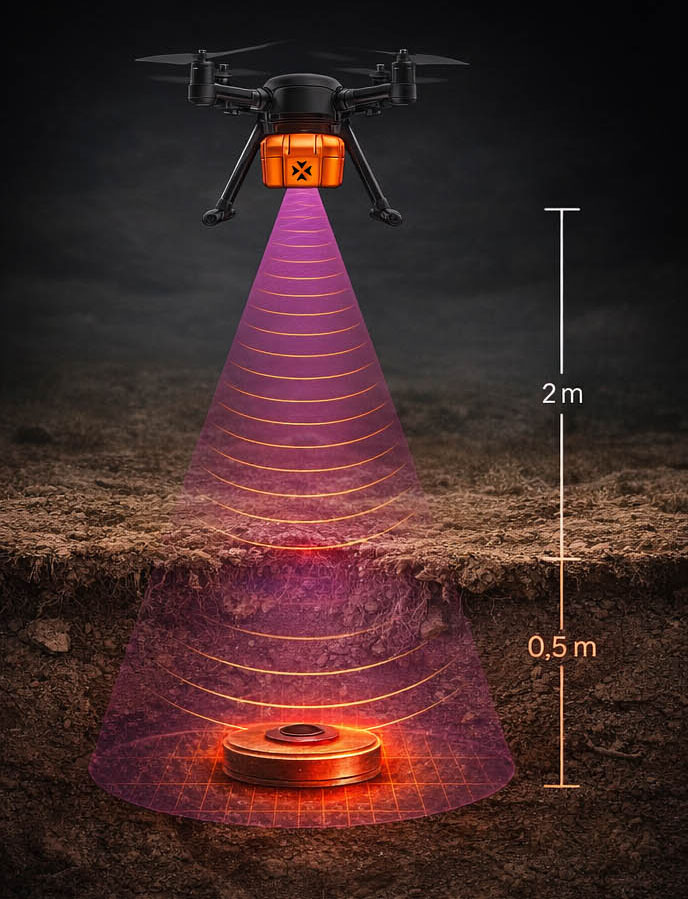

See how Agmis built AI object detection algorithms for Broswarm's autonomous drone platform — identifying buried and surface-level explosive threats across metal, plastic, and rubber materials in four terrain types.
Why AI Companies Are Buying Data – and What It Signals
If data were becoming irrelevant, the world’s largest AI companies would not be spending billions to acquire it. The opposite is happening – and the reason tells you something important about which data still has value.
According to Epoch AI’s 2024 analysis, the public internet contains approximately 300 trillion tokens of quality human-generated text. Current projections suggest base models will have effectively absorbed this entire corpus by 2026-2032. Freely available, high-quality general training data is running out. The AI companies that need it know this.
$
$4.8B to $22.6B by 2034
The market for AI training data licensing is projected to nearly quintuple, driven almost entirely by demand from large language model developers.
$
OpenAI, Anthropic actively licensing domain data
Major AI labs are in licensing negotiations with media organizations and biotech firms – acquiring precisely the proprietary, domain-specific data that is not freely available online.
$
~300 trillion tokens – and it’s running out
The public internet’s quality text corpus will be effectively absorbed by base models within the decade. General data is commoditizing. Specific operational data is what retains strategic value.
This tells you something directly useful. When the largest AI developers are paying a premium for domain-specific proprietary data, it confirms the pattern: general data is becoming commoditized, and specific operational data – the kind only your business generates – is what retains strategic value. The question is whether you are treating yours accordingly.
The implication for businesses is worth sitting with. Data you assumed was protected because it was proprietary may already be partially absorbed into base models through second-order routes – licensed from partners, approximated from adjacent domains, or synthesized from what the model already knows. The safe assumption is that less of your data advantage is uniquely yours than you think.
The Three Zones of Data Value
A useful way to map where your business currently sits is across three zones, defined by the relationship between base model capability and your proprietary data.
| Zone | Description | Risk level |
|---|---|---|
| Zone 1: Data-only | Decisions made purely from accumulated data, no foundation model involvement. Dominant before 2022. | Highest risk |
| Zone 2: Hybrid | Base models and proprietary data work together. Foundation model handles general patterns; your data provides domain context. | Best near-term value |
| Zone 3: Last-mile advantage | Base models handle 70-90% of the task. Your data covers the residual – operational context, edge cases, real-time signals no general model can replicate. | Durable advantage |
The honest question for most leadership teams is this: how many of your AI initiatives are still operating in Zone 1, using only accumulated data, when the base model capability to replace that approach has existed for two years? And equally: for the processes that belong in Zone 3, do you know precisely what data creates the residual advantage – and are you actively generating more of it?
What Data Still Holds Its Value
Data inflation does not mean all data becomes worthless. It means the data that was valuable because it was voluminous is losing ground, while data that is valuable because it is specific, current, or grounded in your operational reality is gaining it.
Three categories consistently retain and grow in value.
→
Real-time operational data
Foundation models have knowledge cutoffs. They cannot tell you what your production line is doing right now, what a customer said to your support team this morning, or what your sensor network detected in the last hour. Data that is live and current retains value precisely because no base model can have it.
→
Edge cases and operational anomalies
General models are trained on what is common. Your environment generates what is specific – the unusual failure mode in your equipment, the atypical customer behavior in your market, the sensor reading that no public dataset contains. These anomalies, properly retained, are the data that base models cannot approximate from the internet.
→
Customer feedback loops
How your customers respond to decisions – what they clicked, what they rejected, what they complained about, what they came back for – is a continuous signal that reflects your specific market. Closing this loop back into your AI system creates a compounding advantage that a competitor cannot replicate from public data alone.
Two Sides of the Same Shift
Data inflation creates different strategic situations depending on where your company starts.
If you have accumulated significant data, the value of that data is declining faster than you may have accounted for. The competitive barrier you assumed it created is lower than it was two years ago – and it will be lower still in two more. That does not mean your data is worthless. It means the window for translating it into a durable advantage by combining it with foundation models is open now, and narrower than it looks.
If you have not accumulated significant data, the barrier that previously blocked you from AI-powered products in your industry is lower than it has ever been. Domains that required years of data collection before you could build a competitive system are now accessible with far less. The opportunity that your better-resourced competitors assumed was closed off by their head start is genuinely more open than it has been before.
In both cases, the direction is the same: stop treating data as a static asset and start treating it as an active input into a system that has to be combined with base model capability to retain its value.
A Practical Framework for Assessing Your Position
The most useful immediate action is not a large data strategy overhaul. It is a targeted audit of where your current AI-driven or data-driven processes sit across the three zones, and what the residual gap between base model capability and your current performance actually is.
1
Identify three high-value processes
Find the processes in your business that currently depend on proprietary data – either for AI models or for decisions made by analysts from data outputs.
2
Test base model capability
For each process, honestly assess what a capable foundation model can do today without your data. Run the test if you have not. The result will often be better than you expect.
3
Measure the gap
Quantify the difference between the base model output and what your current system produces. That gap is your actual data advantage – the residual that your proprietary data creates over and above what the base model already knows.
4
Build the feedback loop
Continuously return real-world outcomes into your data system. The residual advantage only stays durable if the data that creates it keeps getting more specific and more current.
5
Reassess with every major model release
Track this continuously. Every major model release absorbs more capability. Measure whether the gap your data closes has grown or shrunk. This is not a one-time exercise – it is a continuous measurement practice.
The goal is not to conclude that your data is safe or that it has inflated away. The goal is to know, concretely, what each dataset is actually worth in a world where the base model exists.
Conclusion
Data inflation is not a crisis. It is a recalibration – one that many businesses have not yet made, and that creates both risk and opportunity depending on how quickly they move.
The companies that treat this as a reason to abandon their data investments will overcorrect. The companies that ignore it and assume their accumulated data still creates the same protection it did in 2020 will find themselves outflanked by competitors who invested less in data collection but more in understanding how to combine what they have with what base models already know.
The data that matters going forward is not the most data. It is the right data – real-time, specific, grounded in operational reality, and continuously updated. The moat that endures is not the one with the most water. It is the one that keeps refilling from sources the base model cannot reach.
Frequently Asked Questions
Reach out with questions about software development, process automation, or AI-powered solutions - no commitment required.
Drop us a message, send an email, or find our contact details on the page. We'll get back to you promptly to discuss your goals and outline the most effective next steps.


